
Use the right tools. Don’t mess up write-first and read-first databases. Multiply everything. To multiply things, you have to keep them stateless. Don’t let backend do a database’s job – it will always be slower.
Scalability is considered a hard problem to tackle. It’s always presented like it’s something magical done with secret, special tools that only big, million dollar guys are allowed to use.
This is of course not true. There’s nothing magical about it – after all, it’s just the regular code you write with regular programming languages available to everyone.
First of all, it’s about choosing the right tools for the job. You’ve seen the benchmarks, you know that some languages perform better at different things. Some databases are faster to read from and some of them are faster when it comes to writing data.
Even if you’ve chosen the right tech stack for your task, one server could not be enough. And this is where things become interesting.
Of course, you can just go and pick from AWS tiers. But if you want to know how things really work, you should know how to make a scalable setup on bare metal.
Let’s dive in.
Basics
Choosing the right tools
Different programming languages are for different tasks.
For example, Python have very rich and sugary syntax that’s great for working with data while keeping your code small and expressive. But for achieving this, it runs on an interpreter which is by default slower than Go or C which are compiled to run on bare metal.
NodeJS have probably the richest external tool palette available, but it’s single-threaded. To run NodeJS on multiple cores, you have to use something like PM2, but since this you have to keep your code stateless.
Databases are just the same. SQL ones offer the whole Turing-complete language for querying and working with data, but it comes at a cost – without caching, SQL is almost always slower than NoSQL.
Apart from that, databases are often read-first or write-first. It means that some of them are quicker for writing data and some of them performs better on large amounts of reads.
For example, for analytics and other tasks that require a lot of writing but reading is occasional, you might want to choose something write-first, just like Cassandra.
For read-first tasks like displaying news, it’s better to stick with something like MongoDB.
If you need both, just install two databases! This isn’t forbidden. Nothing will break. This is how things should be done.
Multiple servers
When one computer isn’t enough, you just double them. When two isn’t enough, you go for three and so on.
But there’s a pitfall: leaping from one to two may be way harder than going from two to three or from ten to twenty.
To use multiple computers, your backend should be stateless. It means that you have to store all of your data to your databases and leave nothing at backend. This is why functional languages are so popular at the backend, this is why Scala was invented. Functional code is stateless by default.
Different servers should behave exactly the same no matter what. If you have a multitude of stateful servers, they by definition are prone to return different data as a response to the same input because there’ll be two sources of truth: a database and the server’s state. You don’t want to let this happen, trust me.
Go for stateless as soon as possible. It’s better to go for stateless right from the very beginning. If you’re on NodeJS and PM2, you have to keep your code stateless if you want PM2 to multiply your runtime for load-balancing.
Load balancer is the thing that will reroute your request to the least busy server. You obviously need your servers to deliver exactly the same responses for the same requests. This is why we go stateless. As being said for NodeJS, PM2 is a great load-balancing option. If you’re not using Node, go for Nginx.
Sessions? Store them at Redis and allow all of your servers to access it.
Caching and rate limiting
Imagine calculating the same thing every 100 milliseconds for each and every user. This will make your server vulnerable for Slashdot effect – it will basically be DDoS-ed just by users accessing data.
Put a caching middleware in. Only the first user will trigger a data query, and all others will be receiving exactly the same data straight from the RAM.
It comes with downside – that data will be outdated by default. Caching middleware often allows setting the time that have to pass before cache will be reset and thus the data will be eventually refreshed.
Think about your users and their needs and configure cache accordingly. And never, never cache user input. Only the server output should be cached.
Varnish is a great cache option that works with HTTP responses, so it may work with any backend.
Even with caching, different requests blasting every 10ms can bring your server down because your server will be calculating different responses for them. This is why you need a rate limiter – if there’s not enough time had passed since the last request, the ongoing request will be denied. This will keep your server alive.
Dividing responsibilities
If you’re using an SQL database and still calculating external keys with your backend, you’re not using the abilities of your database. Just set up entry relations and allow your database to calculate external keys for you – the query planner will always be faster than your backend.
Backend should have different responsibilities: hashing, building web pages from data and templates, managing sessions and so on.
For anything related to data management or data models, move it to your database as procedures or queries.
Big Data
Even with database cluster, your maximum capacity is limited to your servers’ motherboard. You just can’t put infinite amount of hard drives there. If you want to grow infinitely, you have no other option than using a distributed database. It will store your data on different servers with maximum capacity close to the sum of all your servers’ capacity. If you’re running out of storage, you just add another server to the mix.
With just a master-slave replication, you’ll be doubling and balancing your DB, but the capacity won’t grow infinitely.
Possible bottlenecks
-
Single-threaded, stateful, unscalable server. For load balancing and running many servers, your code has to be stateless.
-
Server does database’s job. Move anything related to the data to the database.
- Single database instance. For load-balancing a database, go for cluster.
-
Read-first vs write-first messed up. Analyze the common tasks and use the database of different type accordingly.
- You’re far away from your clients geographically. Go for CDN.
Setup examples
Kitten

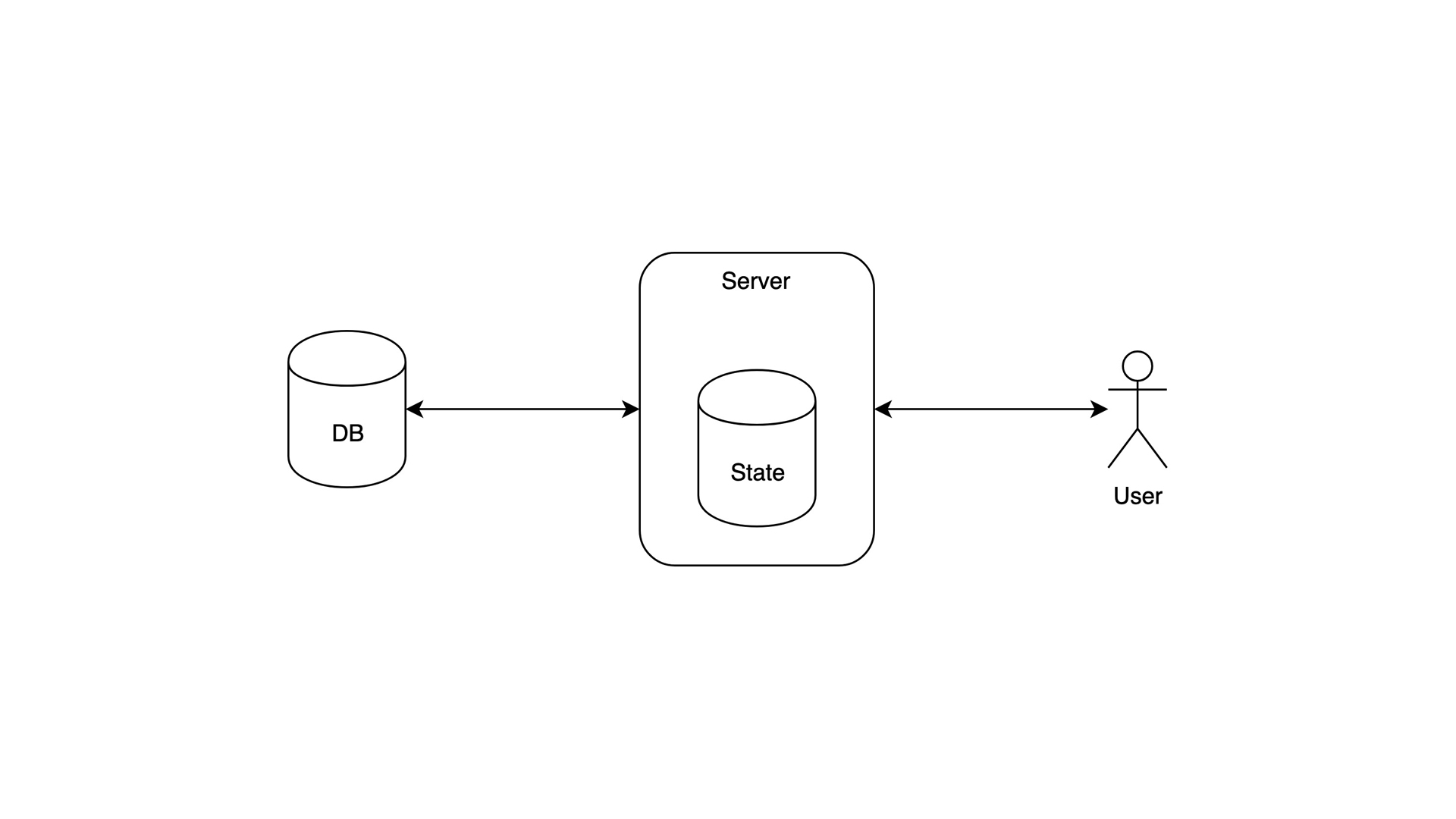
This is your basic setup you can build on a LAMP stack in one evening. It is stateful – it stores sessions and god knows what else right in memory. You guessed it – it doesn’t scale at all. But still, it’s perfect for small weekend projects.
- Data: gigabytes
- Users: thousands
- Bottleneck: Availability. Single server only, easily vulnerable to Slashdot effect
- Tools: your regular LAMP stack.
Cat

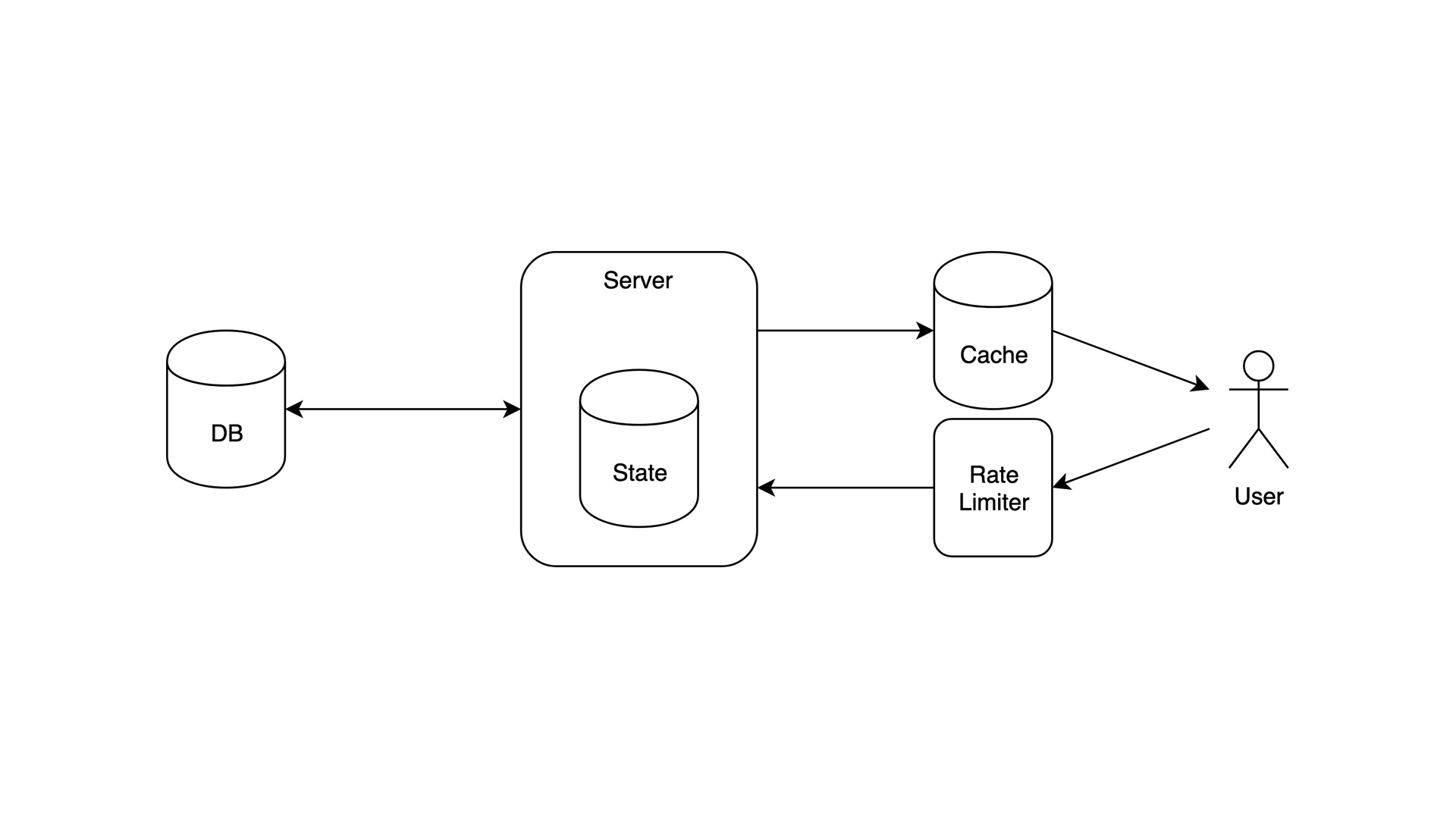
We added cache to the mix. It gained speed, but it’s still unscalable because of stateful architecture. This is what you do when your weekend project got users.
- Data: gigabytes
- Users: tens of thousands
- Bottleneck: Stateful server. Even with cache doing its job, server it still unscalable
- Tools: Express with rate limiter and in-memory cache, MongoDB
Cheetah

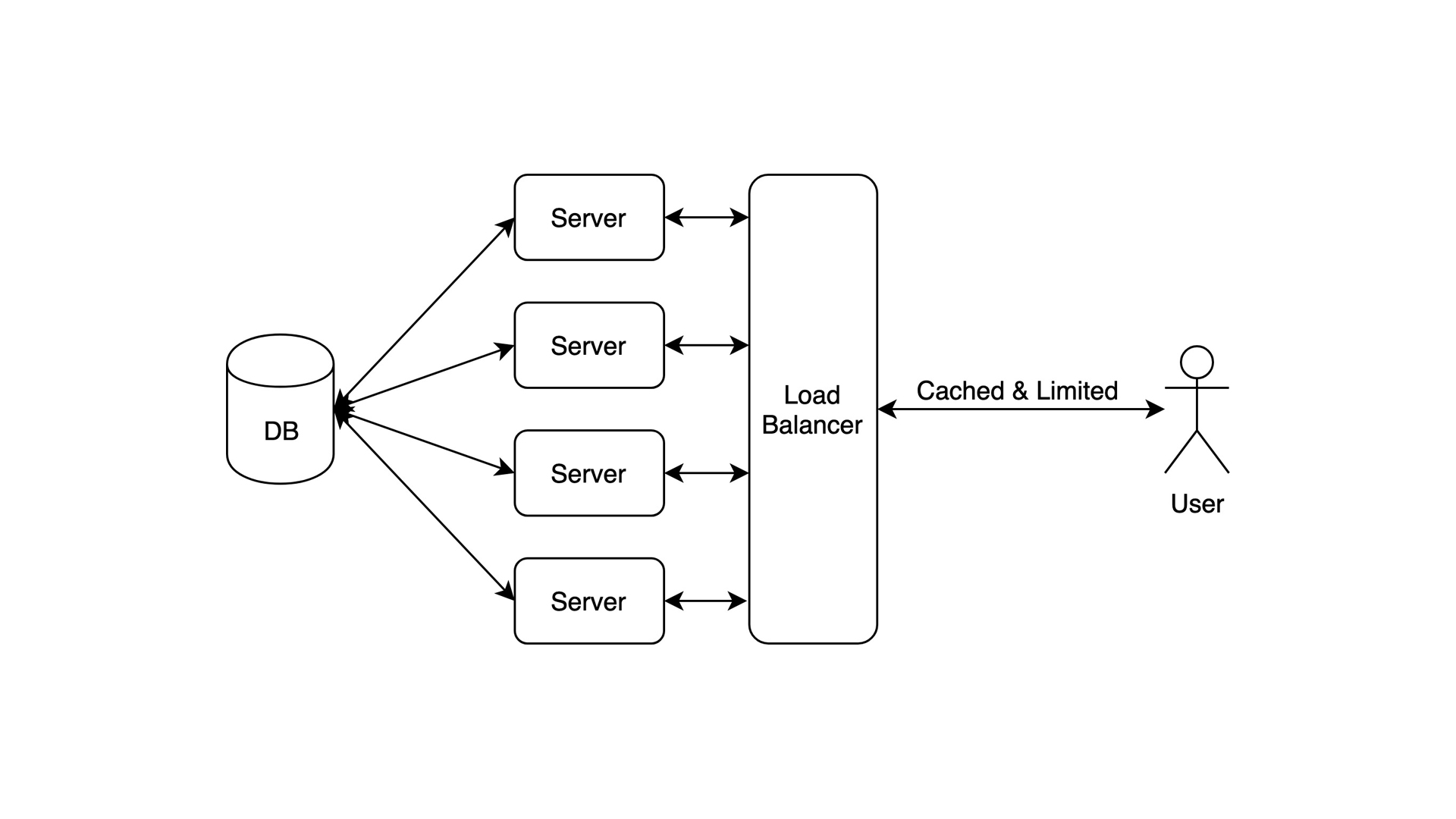
It scales! You can have as many servers as you want. Now you can deal with all that requests that may’ve brought a Cat down, but your database is still runs a single instance and have to deal with all the requests. Despite that, it’s perfect for small projects, e-shops or something like that.
- Data: terabytes
- Users: hundreds of thousands
- Bottleneck: Single DB. Functional languages kick in, the server is scalable. But single DB can fail to deal with many requests
- Tools: Go, Redis cache, MongoDB
Tiger

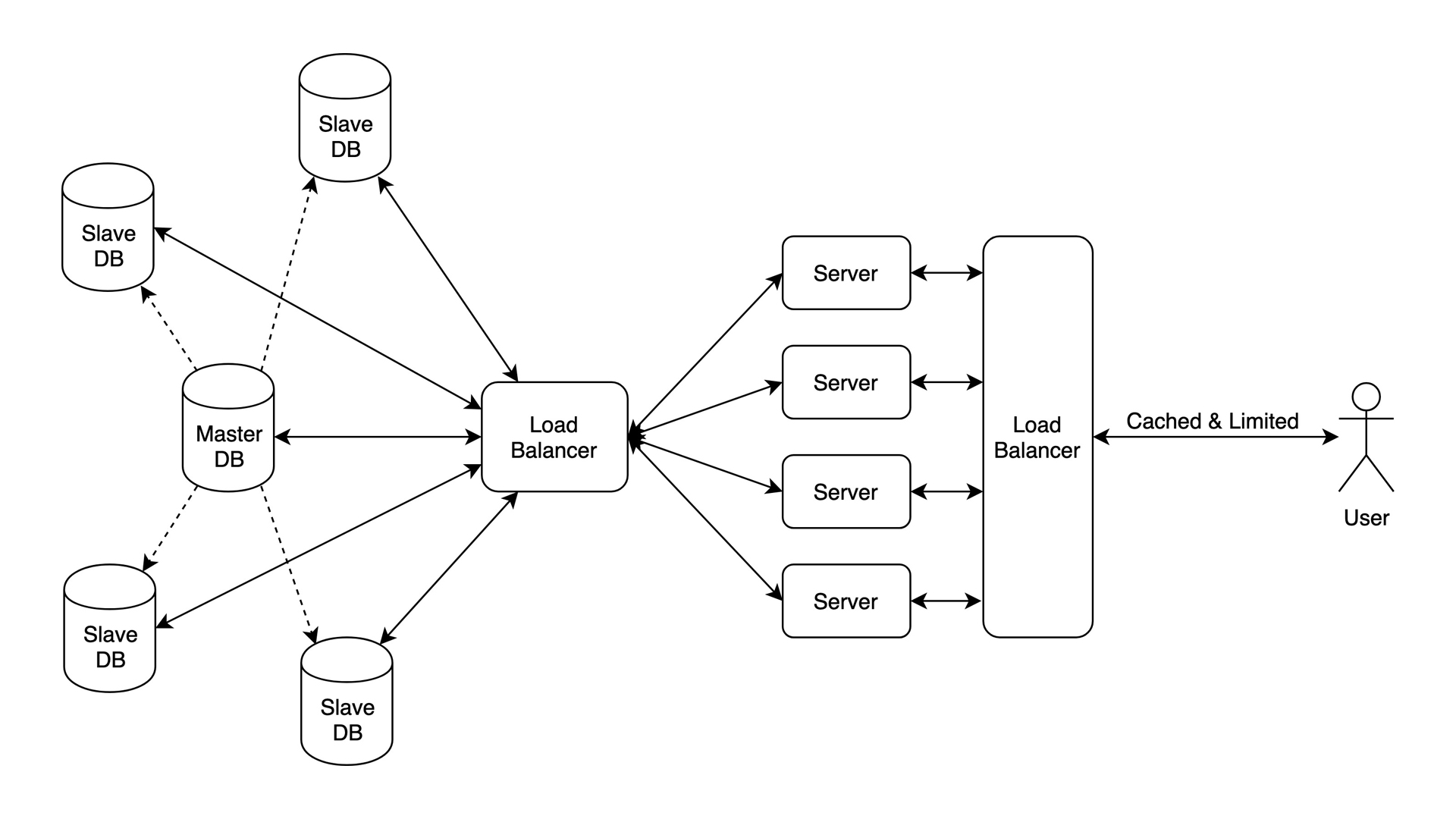
It’s fast. It’s scalable. Look how beautiful it is. DB is balancing requests, as well as your backend. The bottleneck here is when you run a single server or data center, overseas users may have to deal with high latencies just because they’re far away. But still, this setup can handle many of users and is perfect for news website.
- Data: hundreds of terabytes
- Users: millions
- Bottleneck: Distance. The server is fast, but if your user is far away, it can be slow
- Tools: Go, Redis + Cassandra + MongoDB
Lion

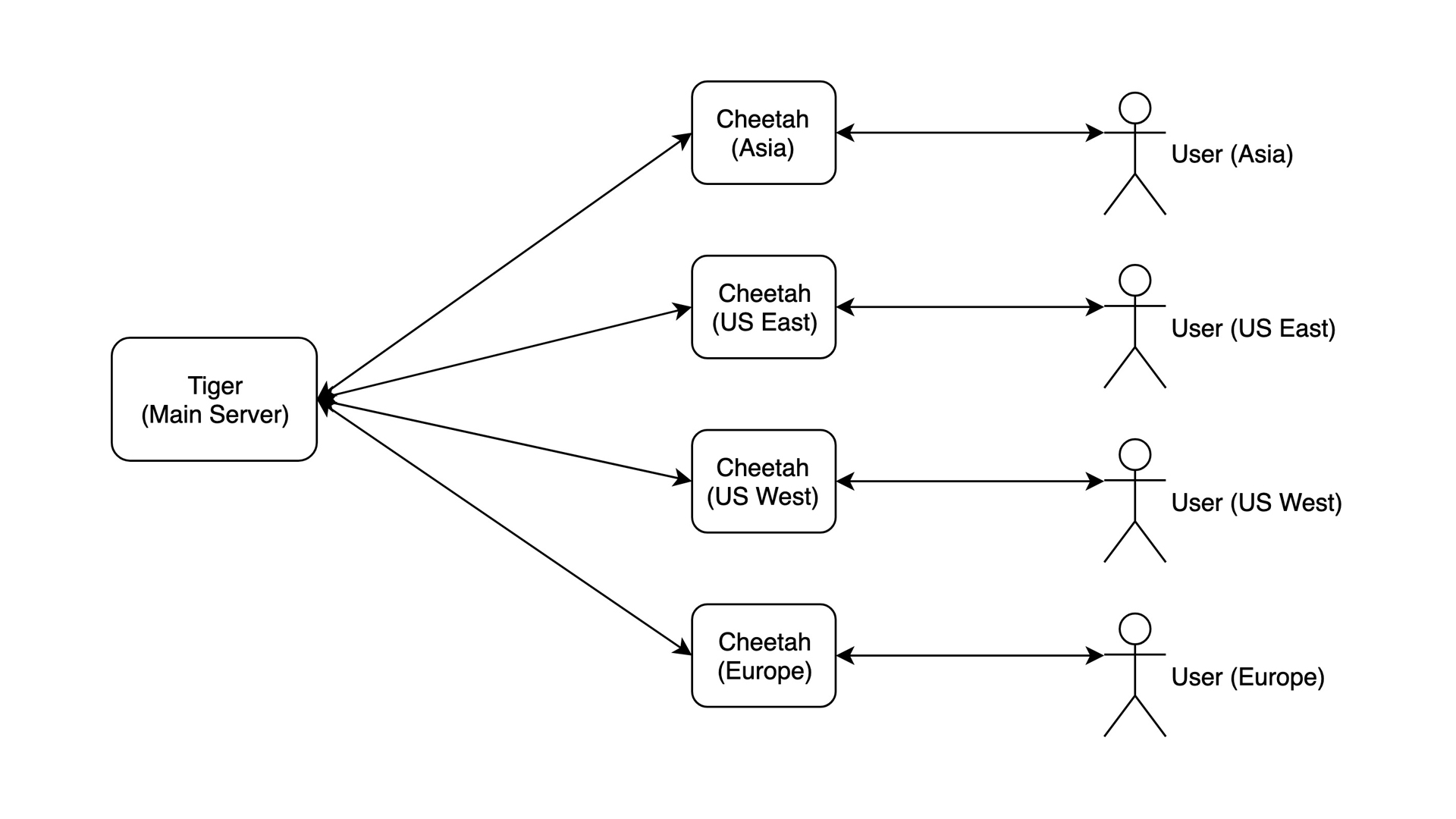
This is a CDN – an entirely different thing. You have multiple servers all over the world geographically, and they can serve the requests just like the master. It’s not like having a cache – they are fully-functional on their own.
Users from different continents are separated with DNS.
Despite that servers are fast, you’re still limited to the capacity of one server. Your DBs are copies of master DB, thus you are limited to master’s capacity.
This is perfect for pretty much anything like hosting providers, large e-commerce and things like that.
- Data: hundreds of terabytes
- Users: tens of millions
- Bottleneck: Big Data. With master-slave replication, you can’t go big on data, you’re limited to the capacity of one DB server.
- Tools: Same but MongoDB is clustered
Sabertooth

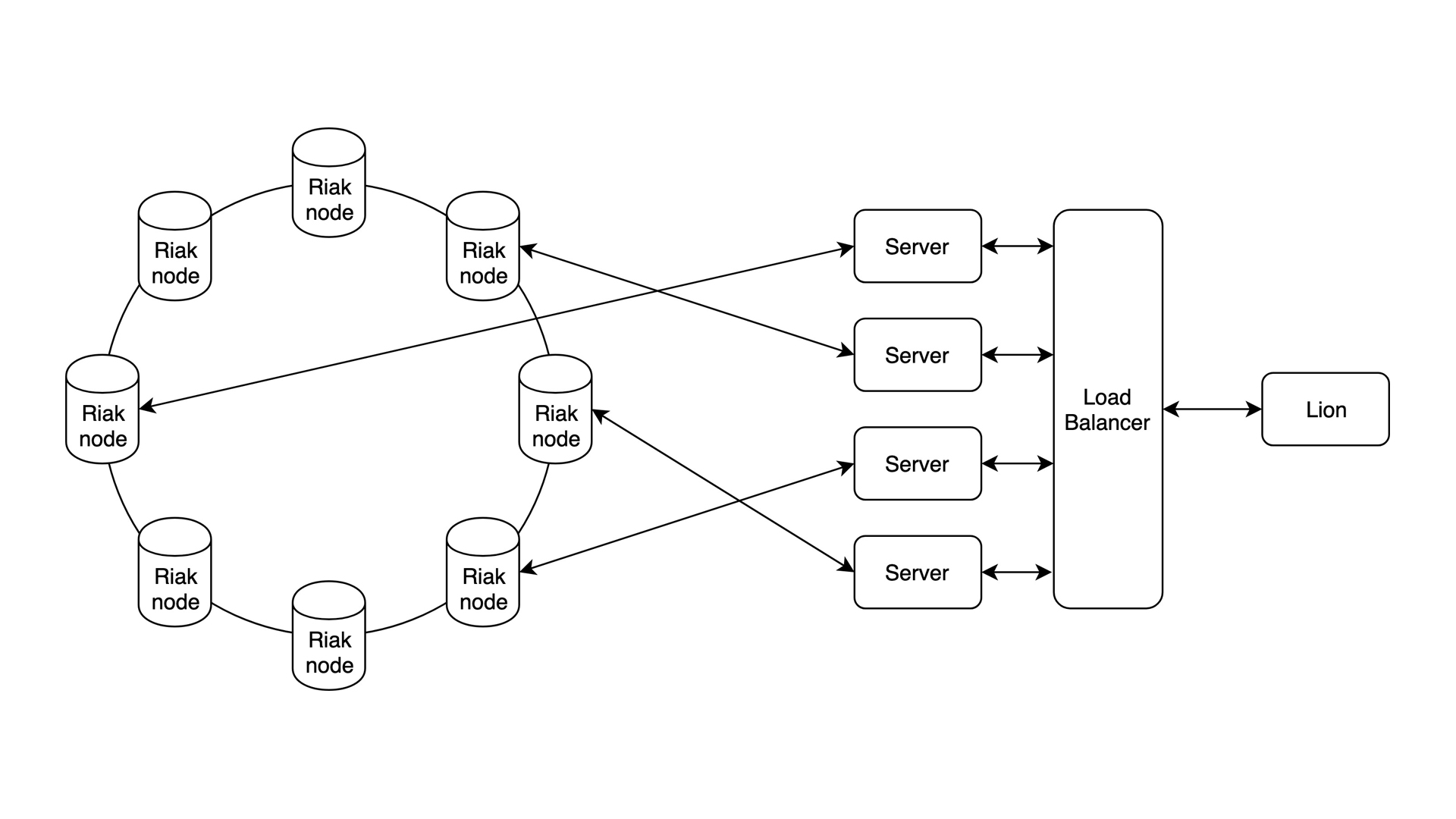
This is the final form. With a graph database like Riak, your capacity is no longer limited. When you’re running low, you just buy a new storage server and add it to the mix.
Perfect for recreating Google or Facebook.
- Data: unlimited
- Users: all of them
- Bottleneck: Price. It costs like a space program.
- Tools: Go, Riak
Wrapping up
We’ve reviewed some of the most common setups for pretty much every project. You don’t have to stick with them – if the task requires that, go and design your own. Just remember that every tool have it’s use and make sure that you’re using the tools that are right for your job.
Keep is scalable, keep is stateless.
Credits
- Cover image – Ellie Brown
- Kitten – Nine Köpfer
- Cat – Liliana Marin
- Cheetah – Cara Fuller
- Tiger – Frida Bredesen
- Lion – Tony Macias
- Sabertooth – DinoAnimals.com
